サイトのSEOを本気で改善したいなら、robots.txtとsitemap.xmlの正しい理解と運用は避けて通れません。この2つのファイルは、Googlebotをはじめとする検索エンジンクローラーがあなたのサイトをどう巡回し、何をインデックスするかを直接コントロールする「司令塔」です。
しかし、書き方を一文字間違えるだけでサイト全体が検索結果から消える危険性もある、非常にデリケートなファイルでもあります。本記事では、Google Search CentralやSitemaps.orgといった一次情報をもとに、2026年の最新仕様に準拠したrobots.txtとsitemap.xmlの書き方を、コピペですぐ使えるテンプレートとともに完全解説します。初心者から中級者まで、これ一本で網羅できる内容になっています。
robots.txtとsitemap.xmlの役割
まず両ファイルの本質的な違いを押さえておきましょう。
混同されがちですが、目的も書き方もまったく異なります。
robots.txtは「クロール制御」のためのファイル
robots.txtはサイトのルートディレクトリに配置するプレーンテキストファイルで、Robots Exclusion Standard(ロボット排除規約)に従って記述します。
たとえばwww.example.comというサイトであれば、www.example.com/robots.txtに配置されます。
robots.txtは検索エンジンのクローラーに対して、サイト内のどのURLにアクセスできるかを伝えるためのものです。
主な用途はサイトへのリクエスト過多を防ぐことであり、ウェブページをGoogleの検索結果から除外するための仕組みではありません。
警告:robots.txtでDisallowしたページでも、外部サイトからリンクされていればGoogleがそのURLをインデックスする可能性があります。
検索結果から完全に除外したい場合はnoindexメタタグやパスワード保護を使う必要があります。
sitemap.xmlは「クロール誘導」のためのファイル
sitemap.xmlは、ウェブマスターが検索エンジンに対してクロール可能なページの存在を知らせるための仕組みです。
最もシンプルな形では、各URLとそのメタデータ(最終更新日、更新頻度、相対的な重要度)を記述したXMLファイルとして提供されます。
Sitemapsプロトコルは「URLを含めるためのプロトコル」であり、「URLを除外するためのプロトコル」であるrobots.txtを補完する関係にあります。
つまり、robots.txtが「入れない場所」を伝えるのに対し、sitemap.xmlは「ぜひ見てほしい場所」を伝えるという違いがあります。

robots.txtの基本構文と書き方
robots.txtは非常にシンプルな構造ですが、ルールを誤解すると致命的な事故につながります。
まずは構成要素を確実に押さえましょう。
必須ディレクティブ「User-agent」
robots.txtは1つ以上のグループ(ルールのセット)で構成され、各グループは1行に1つのルール(ディレクティブ)を含みます。
各グループはUser-agent行から始まり、そのグループが対象とするクローラーを指定します。
アスタリスク(*)を使うとAdsBotを除くすべてのクローラーに適用されます。
AdsBot系のクローラーは明示的に名前を指定する必要があります。
DisallowとAllowの使い分け
Disallowはアクセスを禁止するパス、Allowは許可するパスを指定します。
ルールは大文字小文字を区別する点に注意が必要です。
たとえばdisallow: /file.aspはhttps://www.example.com/file.aspには適用されますが、https://www.example.com/FILE.aspには適用されません。
基本的な書き方は以下のとおりです。
# すべてのクローラーに対して/private/配下を禁止
User-agent: *
Disallow: /private/
Allow: /private/public-info.html
# Googlebotだけ追加で/test/も禁止
User-agent: Googlebot
Disallow: /test/
# サイトマップの場所を明示
Sitemap: https://www.example.com/sitemap.xmlワイルドカードと終端記号
Google、Bing、その他の主要検索エンジンは、パス値に対して限定的な形でワイルドカードをサポートしています。
アスタリスク(*)は任意の有効な文字が0個以上あることを示します。
また、ドル記号($)はURLの末尾を示します。
# すべてのPDFファイルへのクロールを禁止
User-agent: *
Disallow: /*.pdf$
# パラメータ付きURLを禁止
User-agent: *
Disallow: /*?sessionid=ルールの優先順位と競合
クローラーはrobots.txtのルールをURLに照合する際、ルールパスの長さに基づいて最も具体的なルールを使用します。
ワイルドカードを含むものも含めてルールが競合する場合、Googleは最も制限の緩いルールを採用します。
この「最も具体的なルールが優先される」という挙動を理解していないと、意図せず重要ページをブロックしてしまう事故が起こります。
robots.txtの設置場所と動作要件
robots.txtは「正しく書く」だけでなく「正しい場所に置く」ことが必要です。
配置ミスは即座にファイルそのものが無視される結果につながります。
必ずルートディレクトリに配置する
robots.txtファイルは必ずサイトの最上位ディレクトリ(ルート)に、サポートされているプロトコルで配置する必要があります。
robots.txtのURLは他のURLと同様に大文字小文字を区別します。
Google検索でサポートされるプロトコルはHTTP、HTTPS、FTPです。
robots.txtに記述されたルールは、そのrobots.txtがホストされているホスト、プロトコル、ポート番号にのみ適用されます。
つまり、サブドメインごとに別個のrobots.txtが必要になります。
サブドメイン・プロトコルごとに別ファイル
ホストとはURLにおいてプロトコル(http://やhttps://)の後からパスまでの部分を指します。
m.de.example.comというホストは、m.de.example.com、de.example.com、example.comという3つの可能なホストを含意し、それぞれが独自のrobots.txtを持てます。
オリジンとはプロトコル+ホストの組み合わせです。
ファイル形式とサイズ制限
robots.txtはUTF-8でエンコードされたプレーンテキストである必要があり、Googleが処理するサイズ上限は500キビバイトです。
これらは単なる推奨ではなく、2022年にRFC 9309: Robots Exclusion Protocolとしてインターネット標準として正式に成文化されており、準拠クローラーが改行や文字エンコーディングをどう解析すべきかが厳密に定められています。
sitemap.xmlの基本構造と必須タグ
sitemap.xmlはXMLの形式に従う必要があり、必須タグと任意タグが厳密に定められています。
仕様から逸脱したサイトマップは無視されます。
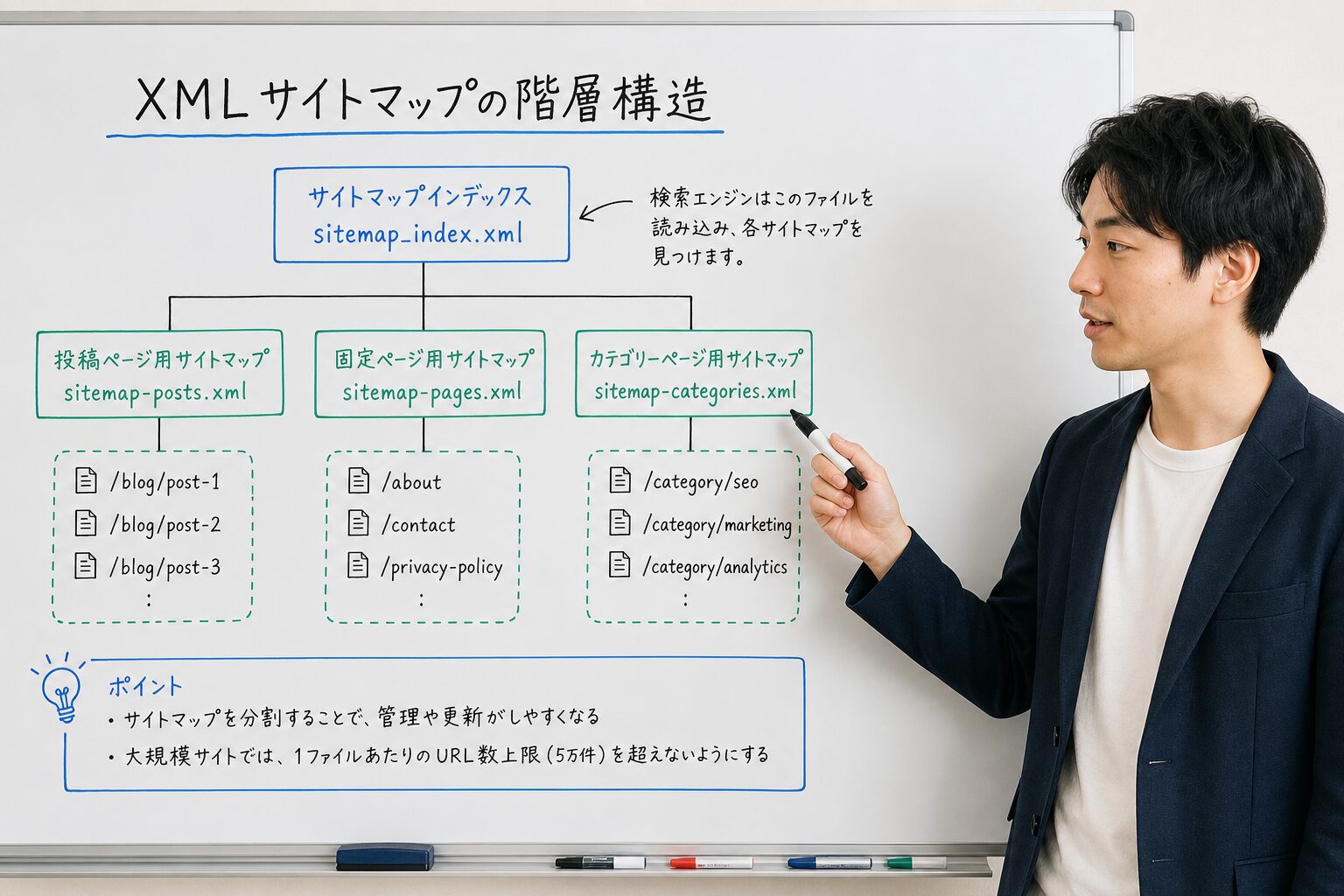
必須要素「urlset」「url」「loc」
名前空間(プロトコル標準)は<urlset>タグ内で指定します。
各URLに対して<url>エントリを親XMLタグとして含め、各<url>親タグの中に<loc>子要素を含めます。
他のタグはすべて任意で、これらの任意タグのサポートは検索エンジンによって異なる場合があります。
Google公式の最小構成例は以下のとおりです。
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.example.com/foo.html</loc>
<lastmod>2026-01-15</lastmod>
</url>
</urlset>任意要素「lastmod」「changefreq」「priority」
重要なポイントとして、Googleは<priority>と<changefreq>の値を無視します。
Googleは<priority>と<changefreq>の値を無視し、<lastmod>の値はそれが一貫性をもって検証可能に正確である場合(たとえばページの実際の最終更新時刻と比較して)のみ使用します。
つまり、lastmodを偽装して頻繁に更新したように見せかけても効果がないどころか、信頼性を損ねる可能性があります。
lastmodはページの実コンテンツが変更されたタイミングだけを正直に反映させましょう。
サイズ・URL数の上限
すべてのフォーマットにおいて、単一のサイトマップは50MB(非圧縮)または50,000URLが上限です。
これを超える場合はサイトマップを分割し、任意でサイトマップインデックスファイルを作成して、その1つのインデックスファイルをGoogleに送信できます。
sitemap.xmlの応用:インデックスと拡張
大規模サイトや特殊コンテンツを扱う場合、単一のsitemap.xmlだけでは不十分です。
インデックスファイルや拡張サイトマップを活用しましょう。
サイトマップインデックスファイル
50,000URLを超えるサイトでは、サイトマップを複数に分割してインデックスファイルでまとめます。
インデックスから参照されるサイトマップは、サイトマップインデックスファイルと同じサイト上にホストされる必要があります(クロスサイト送信を設定した場合を除く)。
参照されるサイトマップはインデックスファイルと同じディレクトリか、それより下の階層にある必要があります。
Search Consoleの各サイトに対し、最大500個のサイトマップインデックスファイルを送信できます。
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://www.example.com/sitemap-posts.xml</loc>
<lastmod>2026-05-01T18:23:17+09:00</lastmod>
</sitemap>
<sitemap>
<loc>https://www.example.com/sitemap-products.xml</loc>
<lastmod>2026-05-10</lastmod>
</sitemap>
</sitemapindex>画像・動画・ニュースサイトマップ
画像サイトマップと動画サイトマップは、画像検索や動画検索でのランキング能力を向上させるためのものです。
動画サイトマップでは、埋め込みや自動再生に関するデータ、検索結果に表示する推奨サムネイル、公開日、動画の長さなどのメタデータを指定できます。
Vimeoや YouTubeのような外部にホストされている動画にも対応します。
画像サイトマップではライセンス情報、地理的位置、画像のキャプションなどのメタデータを指定できます。
特殊文字のエスケープ処理
すべてのXMLファイルと同様に、タグの値はすべてエンティティエスケープする必要があります。
具体的には、URLに「&」「’」「”」「>」「<」などが含まれる場合、それぞれ&、'、"、>、<に置き換える必要があります。
robots.txtとsitemap.xmlの連携
この2つのファイルは独立しているようで、実は密接に連携させることで真価を発揮します。
robots.txtが「門番」だとすれば、サイトマップは「王国の地図」です。
2026年のSEOにおいて、この2つの相互作用がクロール効率を決定づけます。
robots.txtにSitemap行を記述する
robots.txtファイルの任意の場所にSitemap行を挿入し、サイトマップのパスを指定します。
これにより、次回robots.txtがクロールされたタイミングでGoogleがサイトマップを発見します。
User-agent: *
Disallow: /admin/
Disallow: /tmp/
Allow: /
# 複数のサイトマップも記述可能
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/sitemap-news.xml
Sitemap: https://www.example.com/sitemap-images.xmlクロール禁止URLをサイトマップに含めない
robots.txtでDisallowしているURLをsitemap.xmlに含めるのは矛盾した指示であり、Search Consoleで警告が出ます。
警告:サイトマップにはインデックスさせたい正規URLだけを含め、ブロック対象URLは絶対に入れないでください。
重複コンテンツ扱いされる原因にもなります。
canonical URLとの一貫性
サイトマップを作成する際は、検索結果に表示したいURL(つまり正規URL)を検索エンジンに伝えています。
同じコンテンツが異なるURLでアクセス可能な場合、すべてのURLを含めるのではなく、優先するURLを選んでサイトマップに含めるべきです。
AIクローラーとボット制御の最新事情
2026年のrobots.txt運用では、従来の検索エンジンだけでなく生成AIのクローラー対策が極めて重要になっています。
主要AIクローラーのUser-agent
robots.txtのディレクティブは、Gemini、Perplexity、ChatGPTなど大半の主要AIエンジンによって遵守されます。
特定のAIツールからのアクセスを拒否したい場合は、該当するUser-agent向けのディレクティブを追加します。
AIのUser-agent名は数百種類あり、多くのツールは学習用、インデックス用、ユーザーが起点となる検索用のボットを区別しています。
代表的なAIクローラーの例を挙げると以下のとおりです。
- GPTBot:OpenAIのモデル学習用クローラー
- OAI-SearchBot:ChatGPT検索結果表示用
- ClaudeBot:Anthropicの学習用クローラー
- Google-Extended:Geminiの学習用トークン
- CCBot:Common Crawl(多数のLLMが学習データとして利用)
- PerplexityBot:Perplexityの検索クローラー
学習用ボットと検索用ボットの区別
一般的なボットをブロックするだけでは不十分です。
現代のパブリッシャーは検索可視性を提供するエージェントと、学習データのみを収集するエージェントを区別する必要があります。
たとえばOpenAIのGPTBot仕様では、モデル学習をブロックしつつ、OAI-SearchBotにはChatGPT検索でリンクを表示することを許可できます。
# AI学習用ボットを拒否しつつ、AI検索結果には表示
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# 検索用ボットは許可
User-agent: OAI-SearchBot
Allow: /
User-agent: Googlebot
Allow: /AI対応における誤解
SEO界隈でよくある誤解として「AIボットには独自のallowディレクティブが必要」というものがありますが、これは誤りです。
ほとんどのAIクローラーはREP(Robots Exclusion Protocol)に従うため、robots.txtがすべてのボットを許可していればAIクローラーも巡回します。
すべてのボットを拒否していれば巡回しません。
追加のディレクティブは不要です。
よくある失敗とトラブルシューティング
robots.txtとsitemap.xmlの設定ミスはSEOに致命的な影響を及ぼします。
現場でよく遭遇する失敗パターンを押さえておきましょう。
CSS・JSをブロックして起こる悲劇
開発者がDisallow: /assets/やDisallow: /js/*.jsのような広範なルールを使うと、Googlebotがそれらのファイルを必要としていることを忘れがちです。
これらはDOM(Document Object Model)の構築に必要だからです。
モダンなGooglebotはEvergreen Chromiumのレンダリングエンジンを使用しているため、Core Web Vitals(INPなど)を評価するために人間と同じようにページを「見る」必要があります。
robots.txtがGooglebotのレイアウトファイルへのアクセスを妨げると、ボットには素のスタイルなしのHTMLスケルトンが見えることになります。
2026年のランキング環境では、これはモバイルフレンドリーテストの失敗を招きます。
レスポンシブのメディアクエリを処理するCSSがブロックされていると、Googlebotはサイトがモバイル最適化されていないと判断します。
セキュリティ目的での誤用
警告:robots.txtは誰でも閲覧可能な公開ファイルです。
管理画面のパスを記述すると、むしろハッカーに存在を教えることになります。
/secret-admin-login/をrobots.txtで隠そうとすると、それは単にハッカーにその存在を宣伝しているだけになります。
機密ページを守りたい場合は、認証・パスワード保護・IP制限といったサーバー側の防御を必ず併用してください。
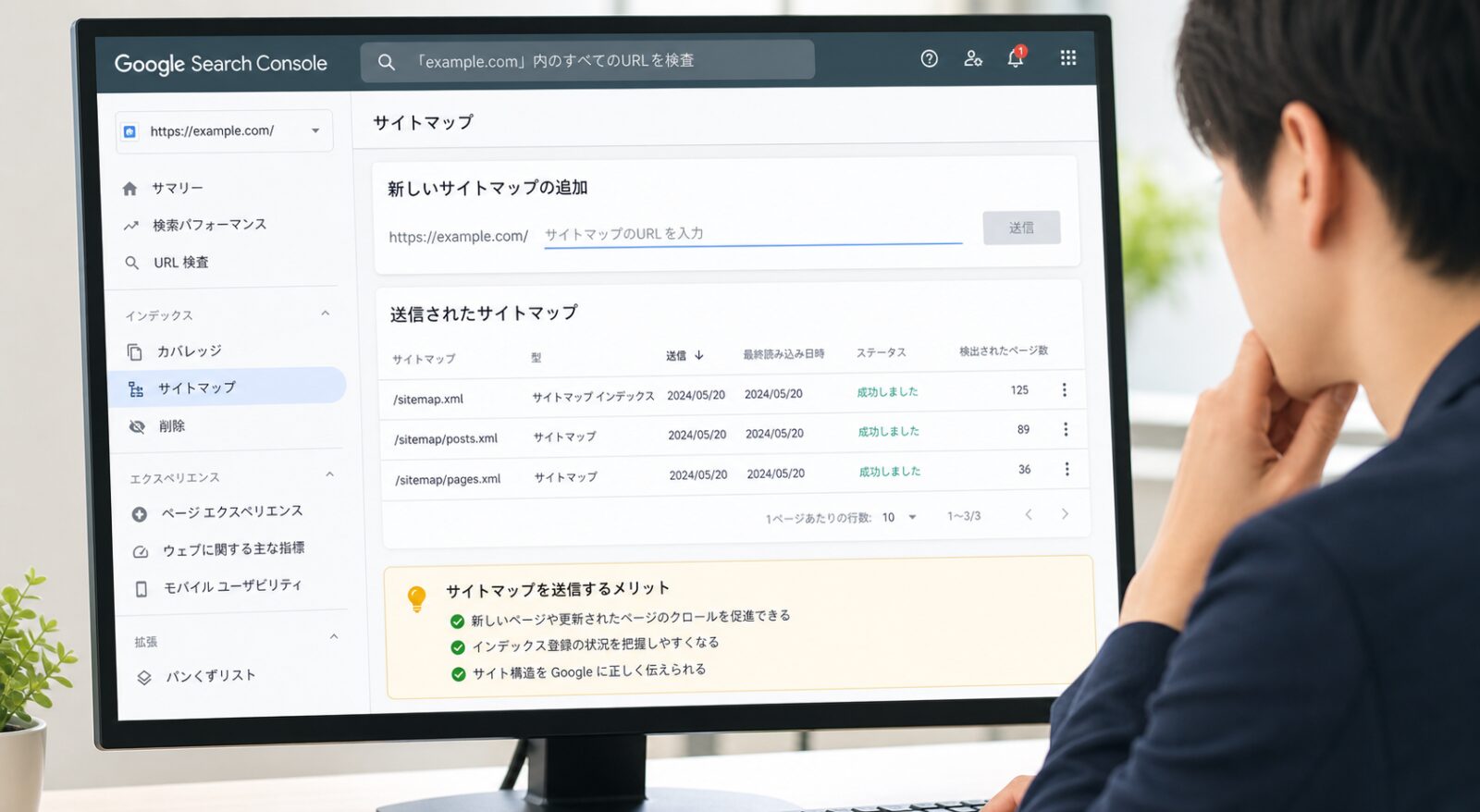
Search Consoleでの検証手順
設定後は必ずGoogle Search Consoleで動作を検証します。
robots.txtレポートは、サイトの上位20ホストについてGoogleが発見したrobots.txtファイル、最終クロール日時、警告やエラーを表示します。
緊急時にはrobots.txtの再クロールをリクエストすることもできます。
サイトマップの送信もSearch Consoleの「サイトマップ」セクションから行います。
送信後はステータスが「成功」になっていること、検出URL数が想定どおりであることを必ず確認しましょう。
「取得できませんでした」エラーが出る場合は、サーバーがGooglebotにアクセスを許可しているか、robots.txtでブロックしていないかを再確認します。
実務で使えるテンプレート集
ここでは現場のユースケース別に、コピペで使えるテンプレートを提示します。
自社サイトに合わせて調整してください。
WordPressサイト向けの標準構成
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-includes/
Disallow: /?s=
Disallow: /search/
Disallow: /*?replytocom=
Sitemap: https://www.example.com/sitemap_index.xmlECサイト向けの構成
User-agent: *
# カート・チェックアウト・マイページは非インデックス
Disallow: /cart/
Disallow: /checkout/
Disallow: /mypage/
Disallow: /search/
# 絞り込みパラメータのクロール抑制
Disallow: /*?color=
Disallow: /*?size=
Disallow: /*?sort=
# 商品画像はインデックスさせたい
User-agent: Googlebot-Image
Allow: /images/products/
Sitemap: https://www.example.com/sitemap-products.xml
Sitemap: https://www.example.com/sitemap-categories.xml開発・ステージング環境用
本番環境でないサイトでは、検索エンジンへのインデックスを完全に防ぐ必要があります。
User-agent: *
Disallow: /警告:本番リリース時にこのDisallow: /を消し忘れる事故が後を絶ちません。
デプロイチェックリストに必ず「robots.txtの内容確認」を入れてください。
加えて、ステージング環境ではBasic認証を併用することを強く推奨します。
まとめ:継続的な運用が成果を生む
robots.txtとsitemap.xmlは、一度書いて終わりのファイルではありません。
サイト構造の変更、新規コンテンツの追加、新しいAIクローラーの登場など、定期的な見直しが必要です。
本記事の要点を整理すると以下のとおりです。
- robots.txtは「クロール制御」、sitemap.xmlは「クロール誘導」と役割が異なる
- robots.txtはルートディレクトリにUTF-8で配置し、サブドメインごとに別ファイルが必要
- sitemap.xmlは50,000URL/50MBが上限、超える場合はインデックスファイルで分割
- Googleはchangefreqとpriorityを無視するため、lastmodの正確性に注力する
- CSS・JSのブロックはレンダリング失敗を招くため絶対に避ける
- 2026年はAIクローラーの区別が新たな運用ポイントになっている
- 設定後は必ずGoogle Search Consoleで検証する
最終的に重要なのは、robots.txtとsitemap.xmlを連動させ、クローラーに「何を見てほしくないか」と「何を最優先で見てほしいか」を明確に伝えることです。
この基本が正しく機能していれば、コンテンツSEOの効果は最大化されます。
本記事のテンプレートをベースに、ぜひ自社サイトの設定を一度総点検してみてください。
より詳細な仕様は、Google Search Centralのrobots.txtガイドおよびSitemaps.orgのプロトコル仕様という一次情報を確認することを強くおすすめします。